从事软件开发的Human Techno System公司(东京中央区)与东北大学共同开发了一项技术,可以使有语言障碍的人合成其原来清晰的声音。因ALS(肌萎缩性侧索硬化症)等疾病或事故而导致语言发音不清的人可以通过该技术恢复健康时的声音。该技术计划2~3年内实现实用化。

完全按照用户的语音语调读出输入的句子(供图:Human Techno System)
当在电脑中输入“早上好。今天的天气也不错”时,宛若再现了自己在讲话时的声音从电脑中发了出来。此次开发的就是为那些因疾病或事故等而出现语言障碍的人带来这种生活场景的技术。
该技术让人工智能(AI)学习语言障碍者自身的声音和健康人的声音,然后以语言障碍者本人的语音语调合成清晰的声音。由此,语言障碍者可以获得“第二个声音”。如果将该AI嵌入软件中,就能以实现支持使用平板电脑等输入或通过视线输入文本的声音合成系统。
“以往的声音合成系统以如实再现所学习声音的特征为目的,因此有语言障碍的人很难使用”,在Human Techno System公司负责声音合成软件开发的渡边聪说道。如果学习的声音数据缺乏抑扬顿挫感,或者讲话速度非常慢,那么合成的声音就容易不清晰。
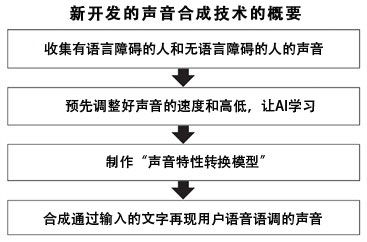
研究团队此次开发了在保持清晰的抑扬顿挫感和节奏的同时,仅将语音语调转换成用户本人的声音的技术,克服了这个挑战。使用了名为“生成式对抗网络(GAN)”的AI法等。
该技术还能节省提供声音数据的用户的时间和精力。该公司过去开发的声音合成软件需要让用户朗读和录制近千种句型。而此次只需约100~200种。如果因疾病的进展等而难以朗读时,也可以使用过去录制的声音。
语言障碍者的声音数据质量各不相同,比如声音过于单调,或者因为用力而导致声音剧烈起伏等。因此,研究团队调整了让AI学习的声音的速度和高低,提高了声音合成的质量。
未来打算与医疗机构和NPO法人等推进验证实验。“合成的声音是否‘像本人’还存在很大的主观性”(渡边),因此将收集用户及其家人的反馈。
该技术针对的症状也将扩大到脑瘫等疾病上。有语言障碍的儿童也将成为目标,需要改良声音收录法和软件使用方法。该软件的目标价格为几十万日元。
日文:高崎文、《日经产业新闻》,2022/5/2
中文:JST客观日本编辑部