6月26日,日本信息通信研究机构(NICT)宣布,该机构的通用通信研究所成功开发出适用于21种语言的高质量且高速运行的神经元语音合成技术。利用该技术,仅用0.1秒就能在单个CPU内核上高速合成时长1秒钟的语音。该技术比现有模型快约8倍,并实现了在未联网的智能手机上,在短短0.5秒内实现从文本到语音的高速生成。
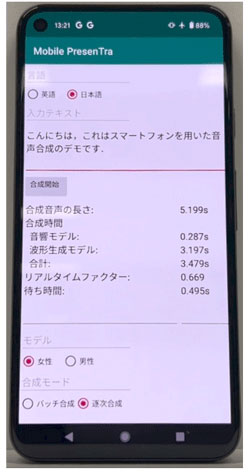
图1:安装在中端智能手机上的语音合成模型(供图:信息通信研究机构(NICT))
通用通信研究所已将此次开发的21种语言语音合成模型搭载在NICT运营的智能手机多语种语音翻译应用程序voicetra的服务器上,并向一般公众开放。今后将通过商业许可等方式将其应用于多语种语音翻译、导航等各种语音应用中。
该成果将于9月在国际语音通讯协会(International Speech Communication Association, ISCA)主办的国际会议INTERSPEECH2024的Show&Tell上发布。
通用通信研究所将在公开为语音翻译验证实验而运行的智能手机语音翻译应用voicetra的同时,通过商用许可实现社会应用。。
用人的声音将翻译后的文本读出来的文本语音合成技术,与语音识别和机器翻译一样,对实现多语种语音翻译技术而言非常重要。
近年来,随着神经元网络技术的导入,文本语音合成的音质得到了显著改善,已经发展到可以与人声媲美的程度,然而,庞大的计算量仍然是一个较大的问题,因此在未联网的智能手机上进行语音合成,此前一直被认为是完全不可能的。
另一方面,NICT在目前正在推进的中长期计划中研究开发多语言同声传译技术,由于同声传译需要在不等说话人说完的情况下顺次说出翻译的语言,因此与语音识别和机器翻译一样,需要文本语音合成的高速化。
文本语音合成模型包括由将输入文本转换为中间特征量(将语音波形划分为短帧并分析每帧的频率而获得的特征)的“声音模型”以及将中间特征量转换为语音波形的“波形生成模型”构成。
其中,在利用模拟人脑神经细胞神经元的神经元网络进行语音合成的“神经元语音合成”的声音模型中,Transformer型编码器+Transformer型解码器的神经元网络被广泛应用于机器翻译领域、语音识别、ChatGPT等大规模语言模型中,是此前的主流。
相比之下,通用通信研究所通过将近年来开始在图像识别领域应用的高速、高性能ConvNeXt型编码器+ConvNeXt型解码器神经网络导入声音模型,在不降低质量的情况下实现了比既往方法快3倍的速度。
此外,通用通信研究所还进一步发展了能够合成与人声相匹敌的原有语音波形生成模型“HiFi-GAN”,2021年将其作为会学习的神经元网络模型“MS-HiFi-GAN”信号处理方式导入进来,在不影响合成质量的情况下,成功地将合成速度提高至了原来的2倍。
2023年又进一步开发出了比“MS-HiFi-GAN”更快的“MS-FC-HiFi-GAN”模型,与既往的“HiFi-GAN”相比,在合成质量不受损的情况下,将合成速度提高至了原来的4倍。
作为这些成果的结晶,此次通用通信研究所使用“声音模型:Transformer型编码器+ConvNeXt型解码器”和“波形生成模型:MS-FC-HiFi-GAN”,实现了更高速度、更高质量的神经元语音合成模型。
由此只需一个CPU内核,就能在0.1秒内高速合成时长1秒钟的语音。即使是在未联网的智能手机(性能和价格为中等的中端产品)上,也能在0.5秒内实现从文本输入到语音合成的高速生成。
3月起已向公众开放
今年3月起,使用了上述最新语音合成技术的voicetra 21种语言的语音已向公众开放。21种语言分别为:日语、英语、中文、韩语、泰语、法语、印度尼西亚语、越南语、西班牙语、缅甸语、菲律宾语、巴西葡萄牙语、高棉语、尼泊尔语、蒙古语、阿拉伯语、意大利语、乌克兰语、德语、印地语、俄语。
原文:《科学新闻》
翻译:JST客观日本编辑部
【论文信息】
期刊:Proceedings of INTERSPEECH 2024
论文:Mobile PresenTra: NICT fast neural text-to-speech system on smartphones with incremental inference of MS-FC-HiFi-GAN for low-latency synthesis